H.264 Video Codec – Deblocking Filter
This filter is also called Loopfilter, In-loop Filter, Reconstruction Filter, Adaptive Deblocking Filter and Post Filter.
Due to coarse quantization at low bit rates and block-based transformation, motion compensation, typically results in visually noticeable discontinuities along the block boundaries, as in Figure 1. If no further provision is made to deal with this, these artificial discontinuities may also diffuse into the interior of blocks by means of the motion-compensated prediction process. The removal of such blocking artifacts can provide a substantial improvement in perceptual quality.
Figure 1: Reconstructed block without Deblocking Filter
H.261 has suggested similar deblocking filter (optional) which was beneficial to reduce the temporal propagation of coded noise because only integer-pel accuracy motion compensation did not play the role for its reduction. However, MPEG-1, 2 did not use the deblocking filter because of high implementation complexity, on the other hand, the blocking artifacts can be reduced by utilizing the half-pel accuracy MC. The half-pels obtained by bilinear filtering of neighboring integer-pels played the role of the smoothing of the coded noise in the integer-pel domain.
Deblocking can in principle be carried out as post-filtering, influencing only the pictures to be displayed. Higher visual quality can be achieved though, when the filtering process is carried out in the coding loop, because then all involved past reference frames used for motion compensation will be the filtered versions of the reconstructed frames. Another reason to make deblocking a mandatory in-loop tool (in-loop filter) in H.264/AVC is to enforce a decoder to approximately deliver a quality to the customer, which was intended by the producer and not leaving this basic picture enhancement tool to the optional good will of the decoder manufacturer.
H.264 uses the deblocking filter for higher coding performance in spite of implementation complexity. Filtering is applied to horizontal or vertical edges of 4 x 4 blocks in a macroblock, as in Figure 2. The luma deblocking filter process is performed on four 16-sample edges and the deblocking filter process for each chroma components is performed on two 8-sample edges.
Figure 2: Horizontal and Vertical Edges of 4 x 4 Blocks in a Macroblock
The filtering process exhibits a high degree of content adaptivity on different levels (adaptive deblocking filter), by adjusting its strength depending upon compression mode of a macroblock (Intra or Inter), the quantization parameter, motion vector, frame or field coding decision and the pixel values. All involved thresholds are quantizer dependent, because blocking artifacts will always become more severe when quantization gets coarse. When the quantization step size is decreased, the effect of the filter is reduced, and when the quantization step size is very small, the filter is shut off. The filter can also be shutoff explicitly or adjusted in overall strength by an encoder at the slice level. As a result, the blockiness is reduced without much affecting the sharpness of the content. Consequently, the subjective quality is significantly improved. At the same time, the filter reduces bit rate by typically 5–10 percent while producing the same objective quality as the non-filtered video.
H.264/MPEG-4 AVC deblocking is adaptive on three levels:
■ On slice level, the global filtering strength can be adjusted to the individual characteristics of the video sequence.
■ On block edge level, the filtering strength is made dependent on inter/intra prediction decision, motion differences, and the presence of coded residuals in the two participating blocks. From these variables a filtering-strength parameter is calculated, which can take values from 0 to 4 causing modes from no filtering to very strong filtering of the involved block edge. Special strong filtering is applied for macroblocks with very flat characteristics to remove 'tilting artifacts'.
■ On sample level, sample values and quantizer-dependent thresholds can turn off filtering for each individual sample. It is crucially important to be able to distinguish between true edges in the image and those created by the quantization of the transform-coefficients. True edges should be left unfiltered as much as possible. In order to separate the two cases, the sample values across every edge are analyzed.
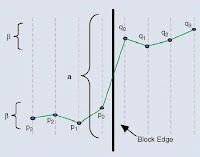
Figure 3: Sample Values inside 2 neighboring 4×4 blocks
For an explanation denote the sample values inside two neighboring 4×4 blocks as p3, p2, p1, p0 | q0, q1, q2, q3 with the actual boundary between p0 and q0 as shown in Figure 3. Filtering of the two pixels p0 and q0 only takes place, if their absolute difference falls below a certain threshold α. At the same time, absolute pixel differences on each side of the edge (|p1 − p0| and |q1 − q0|) have to fall below another threshold β, which is considerably smaller than α. To enable filtering of p1(q1), additionally the absolute difference between p0 and p2 (q0 and q2) has to be smaller than β. The dependency of α and β on the quantizer, links the strength of filtering to the general quality of the reconstructed picture prior to filtering. For small quantizer values the thresholds both become zero, and filtering is effectively turned off altogether.
All filters can be calculated without multiplications or divisions to minimize the processor load involved in filtering. Only additions and shifts are needed. If filtering is turned on for p0, the impulse response of the involved filter would in principle be (0, 1, 4, | 4, −1, 0) / 8. For p1
it would be (4, 0, 2, | 2, 0, 0) / 8. The term in principle means that the maximum changes allowed for p0 and p1 (q0 and q1) are clipped to relatively small quantizer dependent values, reducing the low pass characteristic of the filter in a nonlinear manner.
Intra coding in H.264/AVC tends to use INTRA_16×16 prediction modes when coding nearly uniform image areas. This causes small amplitude blocking artifacts at the macro block boundaries which are perceived as abrupt steps in these cases. To compensate the resulting tiling artifacts, very strong low pass filtering is applied on boundaries between two macro blocks with smooth image content. This special filter also involves pixels p3 and q3.
Boundary strength
The choice of filtering outcome depends on the boundary strength and on the gradient of image samples across the boundary. The boundary strength parameter Bs is chosen according to the following rules:
| p or q is intra coded and boundary is a macroblock boundary | Bs=4 (strongest filtering) |
| p or q is intra coded and boundary is not a macroblock boundary | Bs=3 |
| neither p or q is intra coded; p or q contain coded coefficients | Bs=2 |
| neither p or q is intra coded; neither p or q contain coded coefficients; p and q have different referenc e frames or a different number of reference frames or different motion vector values | Bs=1 |
| neither p or q is intra coded; neither p or q contain coded coefficients; p and q have same reference frame and identical motion vectors | Bs=0 (no filtering) |
The filter is "stronger" at places where there is likely to be significant blocking distortion, such as the boundary of an intra coded macroblock or a boundary between blocks that contain coded coefficients.
Filter decision
A group of samples from the set (p2,p1,p0,q0,q1,q2) is filtered only if:
(a) Bs > 0 and
(b) |p0-q0|, |p1-p0| and |q1-q0| are each less than a threshold α or β [α = (p2 – p0) and β = (q2 - q0)].
The thresholds α and β increase with the average quantizer parameter QP of the two blocks p and q. The purpose of the filter decision is to "switch off" the filter when there is a significant change (gradient) across the block boundary in the original image. The definition of a significant change depends on QP. When QP is small, anything other than a very small gradient across the boundary is likely to be due to image features (rather than blocking effects) that should be preserved and so the thresholds α and β are low. When QP is larger, blocking distortion is likely to be more significant and α, β are higher so that more filtering takes place.
Filtering process for edges with Bs
(a) Bs < 4 {1,2,3}:
A 4-tap linear filter is applied with inputs p1, p0, q0 and q1, producing filtered outputs P0 and Q0 (0<Bs<4).
In addition, if |p2-p0| is less than threshold α, a 4-tap linear filter is applied with inputs p2, p1, p0 and q0, producing filtered output P1. If |q2-q0| is less than threshold β, a 4-tap linear filter is applied with inputs q2, q1, q0 and p0, producing filtered output Q1. (p1 and q1 are never filtered for chroma, only for luma data).
(b) Bs = 4:
If |p2-p0| < β and |p0-q0| < round(α /4):
P0 is produced by 5-tap filtering of p2, p1, p0, q0 and q1
P1 is produced by 4-tap filtering of p2, p1, p0 and q0
(Luma only) P2 is produced by 5-tap filtering of p3, p2, p1, p0 and q0.
else:
P0 is produced by 3-tap filtering of p1, p0 and q1.
If |q2-q0| < α and |p0-q0| < round(β /4):
Q0 is produced by 5-tap filtering of q2, q1, q0, p0 and p1
Q1 is produced by 4-tap filtering of q2, q1, q0 and p0
(Luma only) Q2 is produced by 5-tap filtering of q3, q2, q1, q0 and p0.
else:
Q0 is produced by 3-tap filtering of q1, q0 and p1.
Settings Summary:
This setting controls most important features in Inloop Deblocking filter. In contrast to MPEG-4, the Inloop Deblocking is a mandatory feature of the H.264 standard. So the encoder, x264 in this case, can rely on the decoder to perform a proper deblocking. Furthermore all P- and B-Frames in H.264 streams refer to the deblocked frames instead of the unprocessed ones, which improves the compressibility. There is absolutely no reason the completely disable the Inloop Deblocking, so it's highly recommended to keep it enabled in all cases. There are two settings available to configure the Inloop Deblocking filter:
Strength: This setting is also called "Alpha Deblocking". It controls how much the Deblocking filter will smooth the video, so it has an important effect on the overall sharpness of your video. The default value is 0 and should be enough to smooth out all the blocks from your video, especially in Quantizer Modes (QP or CRF). Negative values will give a more sharp video, but they will also increases the danger of visible block artifacts! In contrast positivevalues will result in a smoother video, but they will also remove more details.
Threshold: This setting is also called "Beta Deblocking" and it's more difficult to handle than Alpha Deblocking. It controls the threshold for block detection. The default value is 0 and should be enough to detect all blocks in your video. Negative values will "save" more details, but more blocks might slip through (especially in flat areas). In contrast positive values will remove more details and catch more blocks.
Remarks: Generally there is no need to change the default setting of 0:0 for Strength:Threshold, as it gives very good results for a wide range of videos. Nevertheless you can try out different settings to find the optimal settings for your eyes. If you like a more sharp video and don't mind a few blocks here and there, then you might be happy with -2:-1. If you like a smooth and clean image or encode a lot of Anime stuff, then you can try something like 1:2. Nevertheless you should not leave the range between -3 and +2!
Figure 4: Reconstructed with Loop Filter